自作ブックマークレット集の下位記事です。
しかしながら私は情報系一切ダメなのでそのつもりで読んでください。
偉そうに解説とかつけてるけど「自分と同じ駆け出しがなんかする助けになればいいなあ」という性質のものに過ぎませんのでご容赦いただく。
ブックマークレット
javascript:(function(){document.execCommand("SelectAll")})();(function() { var selectedText = window.getSelection().toString(); var now = new Date(); var YY = now.getFullYear(); var MM = now.getMonth()+1; var DD = now.getDate(); var s1 = '【scrap】' + document.title + '(' + YY + '-' + MM + '-' + DD + ').txt' ; var s2= document.title + '\r' + document.URL + '\r' + '\r' + selectedText; blob=new Blob([s2],{type:"text/plain"}),url=window.URL,bloburl=url.createObjectURL(blob),a=document.createElement("a");a.download=[s1];a.href=bloburl;a.click();})();
できる事
これをブックマーク欄に放り込んでページ内で起動するとそのページ内容とタイトルと元URLをテキストとしてコピーしたファイルがダウンロードされます。
要するに画像やスクリプトとかを抜きにした簡単なログが得られるので、ネットのお供にちょうどいいかなって。
テキストファイルは容量が非常に少ないので多用してもストレージを圧迫せず、テキストファイルという事で内容の検索も容易であり、後で「あれなんだったかな」となった時に辿りやすくなります。
気になるニュース記事、ポケモンの構築記事、ブログなんかの保存から、お勉強・お仕事の資料集めまで幅広くお使いいただけるかも。
特にニュース記事はすぐ消えるんで今読む余裕ないけど後になったら消えてたとかいやータブ999個開いちゃってさ~(プロアクションリプレイ)みたいな人に向いてそう。
使用例
当ブログのガンガディアについて無限に解釈を語るだけの文章というページで使用するとこんな感じになります。
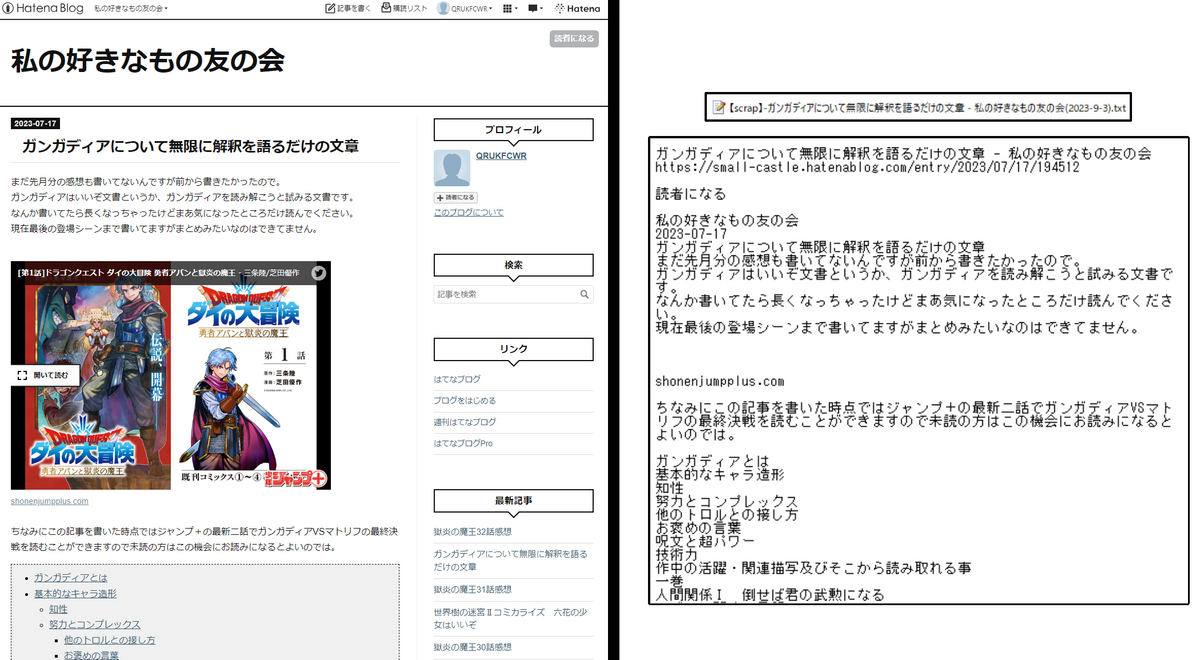
やってる事の解説
挙動としてはCtrl+A的な感じで全体選択を行い文字列としてコピー、
ページタイトル、元ページのアドレス、コピーした文字列をペーストし、テキストファイルとしてダウンロードさせている…はず。
注意点
機能的にはあくまでCtrl+A→Ctrl+C→Ctrl+V程度なので、
なんらかの機能で複数領域に区切られているページはアクティブな領域(テキストボックス等)しか取得できない場合がある他、
ツイッター(X)のタイムライン等画面外領域が描画されなくなる仕様のページは表示されている領域しか取得されず、有効に働きません。
またそもそもテキストで表示されていない(画像や動画だったり等)情報は取得できないため、そういう情報が重要な場合はスクリーンショットを取るなどしてください。
例えば上のガンガディア記事の例ですと、勇者アバン一話の試し読み機能部分は反映されていません。
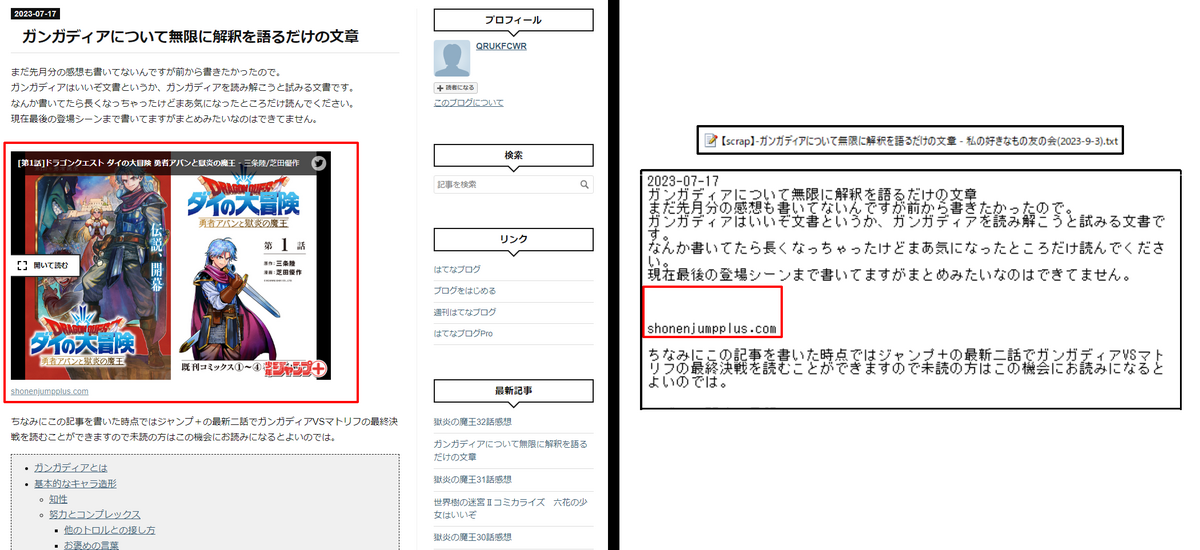
後で『取得』されてませんでしたってのが最もムカつく!ちゃんと確認取ってるか?
応用
【scrap】の部分はこの機能で取得したとわかるようにするためにつけているものですが任意に書き換えて頂くといいと思います。
【後で読む】とか【資料用】とかに変えたものも用意しておくと見分けがつきやすくなっていいかも。
またdocument.title自体は現在のタイトルが取得されるので
表示しているページのタイトルを変更するブックマークレットと併用するのもよく、「限定ショートケーキ」みたいなページのタイトルを「限定ショートケーキ(誕生日用)」とかに書き換えてからダウンロードすれば後で見た時用途や意図がわかりやすくなるはず。
構造の解説
俺は頭悪いんだから解説なんてできねえよ!そもそも何やってるのか自分でもよくわかってねえ!俺が解説してほしいくらいだ!と言いたいけどまあ一応…。
javascript: (function(){document.execCommand("SelectAll")})(); //全体を選択 (function(){ var selectedText = window.getSelection().toString(); //選択した要素をテキストとして取得 var now = new Date(); var YY = now.getFullYear(); var MM = now.getMonth()+1; var DD = now.getDate(); //日付を取得してる var s1 = '【scrap】' + document.title + '(' + YY + '-' + MM + '-' + DD + ').txt' ; //ファイルのタイトルを設定している。(スクラップした事を示すタグ、ページのタイトル、先ほど取得した日付) var s2= document.title + '\r' + document.URL + '\r' + '\r' + selectedText; //ファイルの内容を設定している。(ページのタイトル、URL、ページ内容) blob=new Blob([s2],{type:"text/plain"}),url=window.URL,bloburl=url.createObjectURL(blob),a=document.createElement("a");a.download=[s1];a.href=bloburl;a.click();})(); //生成してダウンロード。タイトルはs1で設定したもの、内容はs2で設定したもの。
えらいところ
元ページのタイトルとURLが取得されるのが、えらいと思います。これが無くて後で元ページにたどりつけなかったら大変です。
取得日時がファイルタイトルに記入されるのが、えらいと思います。プロパティ開けばわかるとはいえぱっと見てわかることは大事です。
すごいなあ、僕にはとてもできない。
~推敲~
元ページのタイトルとURLが記入されるため後から元ページを参照したくなった時に到達できないという事がなくなっています(元ページが残っていれば、ですが…)。
また取得日時がファイルタイトルに記入されるので時系列が把握しやすくなっています。ページ側の内容変更を把握できるというのもそうですし、資料集めなんかに際しては自分のその時の理解度なんかも読み取れるはずです(もっと効率的な方法があるのに全然調べてないから去年の自分は知らなかったんだな…等)。
すごいなあ、僕にはとてもできない。
制作経緯
私はいつも人類の三大欲求である「あー閲覧した全てのページのテキストログ取っておいて後で検索したいなあ…」「毎回コピペするの面倒くさいし自動的に保存できないかなぁ…」という思いに悩まされていたのですが、
ある頃拡張機能とか作ってブラウザをそういうものにすればいいのではないかと思い立ち、いつも同じパソコン使うわけじゃないし、拡張機能って容量制限あるみたいだから無理だなと却下、
しばらくの後にじゃあブックマークレットにするか1クリックで起動すればまあ許容範囲やろと作成しました。
偉い要素はどちらも後付けで、「テキストファイル内にページタイトルとかも無いと後で元サイト確認したくなってもたどり着けないよな」「ファイル名に日付もあるべきじゃね?」という使っていて出てきた新たな要求から追加して現在の形になった次第です。
ユーザー(俺じゃん)の要望から出た機能だからいい出汁が取れているはず。人類三大欲求はこの二つの欲求を足して新たに人類五大欲求として再出発します。
苦労したところ
全て(ブックマークレットなんて自作したことなかったので)。
そもそもページ内容を全選択してテキストにする方法が全く分からなかった。